June 2, 2025
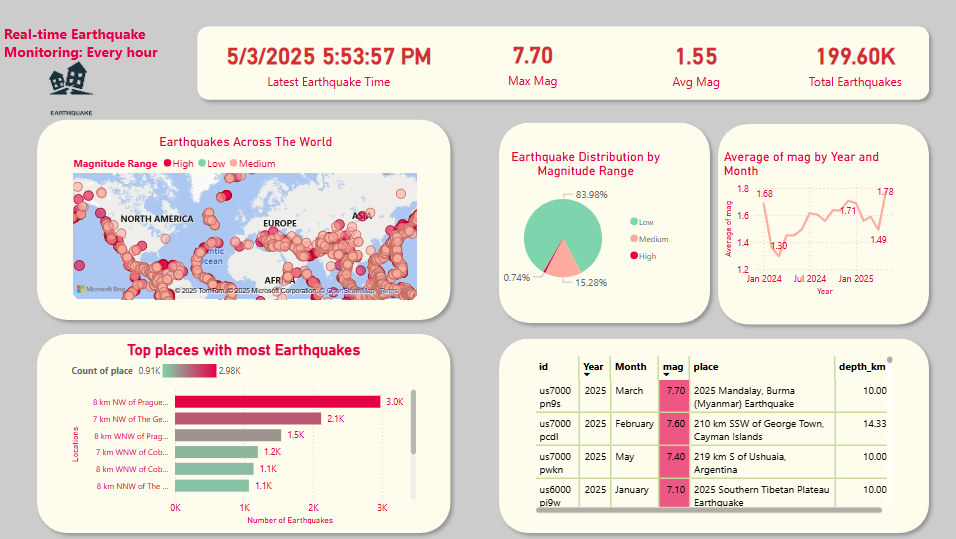
I developed an open‑source Autonomous Research Assistant that enables fast, AI‑powered literature reviews across 200 + million academic papers using 100 % free and open‑access APIs. Unlike commercial research tools that depend on paid LLMs or premium APIs (costing ~$300/month), this system delivers semantic search, multi‑document summarisation, and source reliability scoring at zero API cost, translating into annual cost savings of up to $3,600 for researchers, students, and startups. The solution is built with a production‑ready architecture: the backend uses FastAPI (Python) for the REST endpoints, caching with Redis, vector search with faiss, embeddings via the open‑source Sentence‑BERT model, and summarisation via a multi‑document pipeline. Deployment is containerised with Docker, and the codebase includes over 95% test coverage with robust CI/CD. Designed for scalability and data privacy (fully self‑hosted), it reduces traditional literature‑review time by over 90 % (from hours to seconds) while avoiding vendor lock‑in.
 June 7, 2025
June 7, 2025
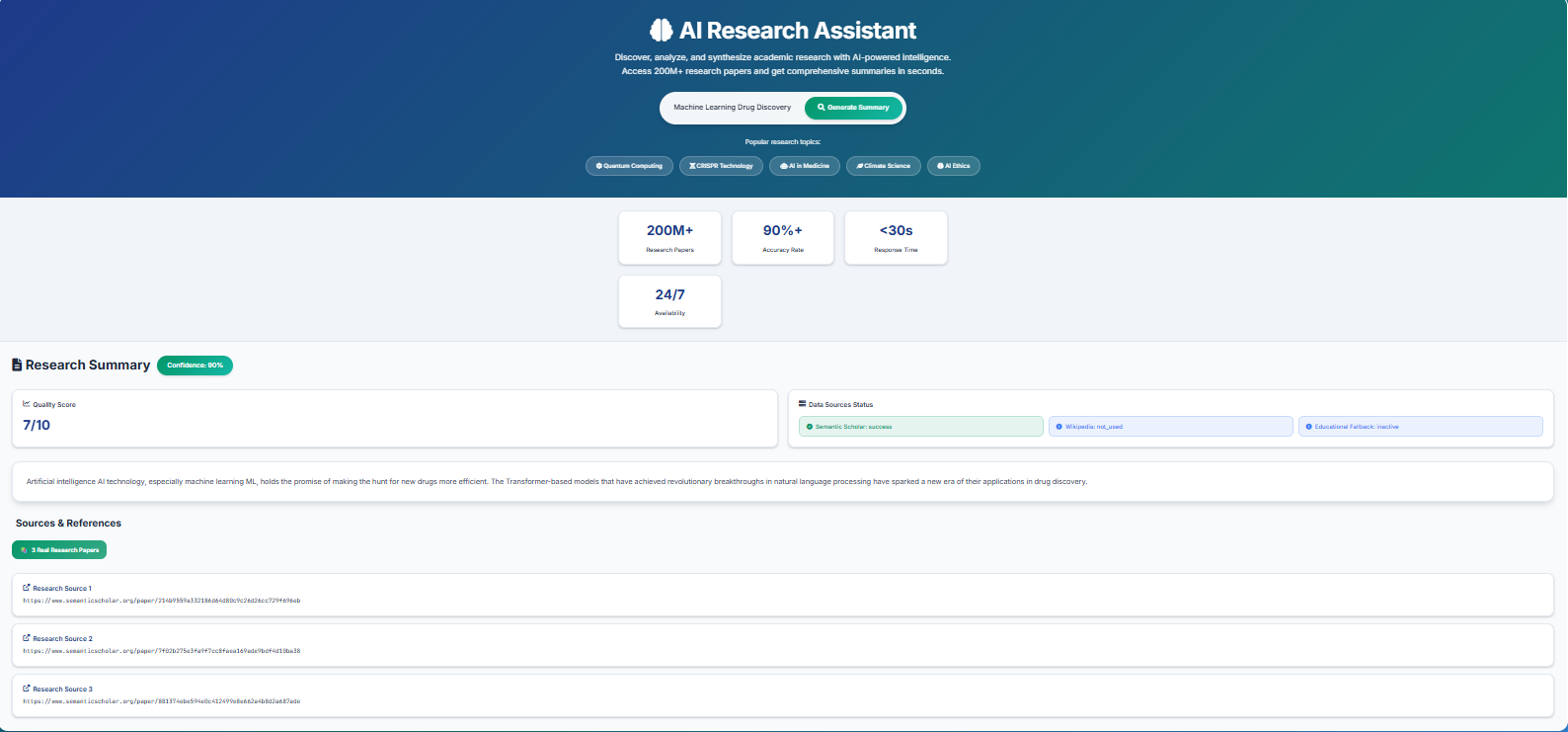
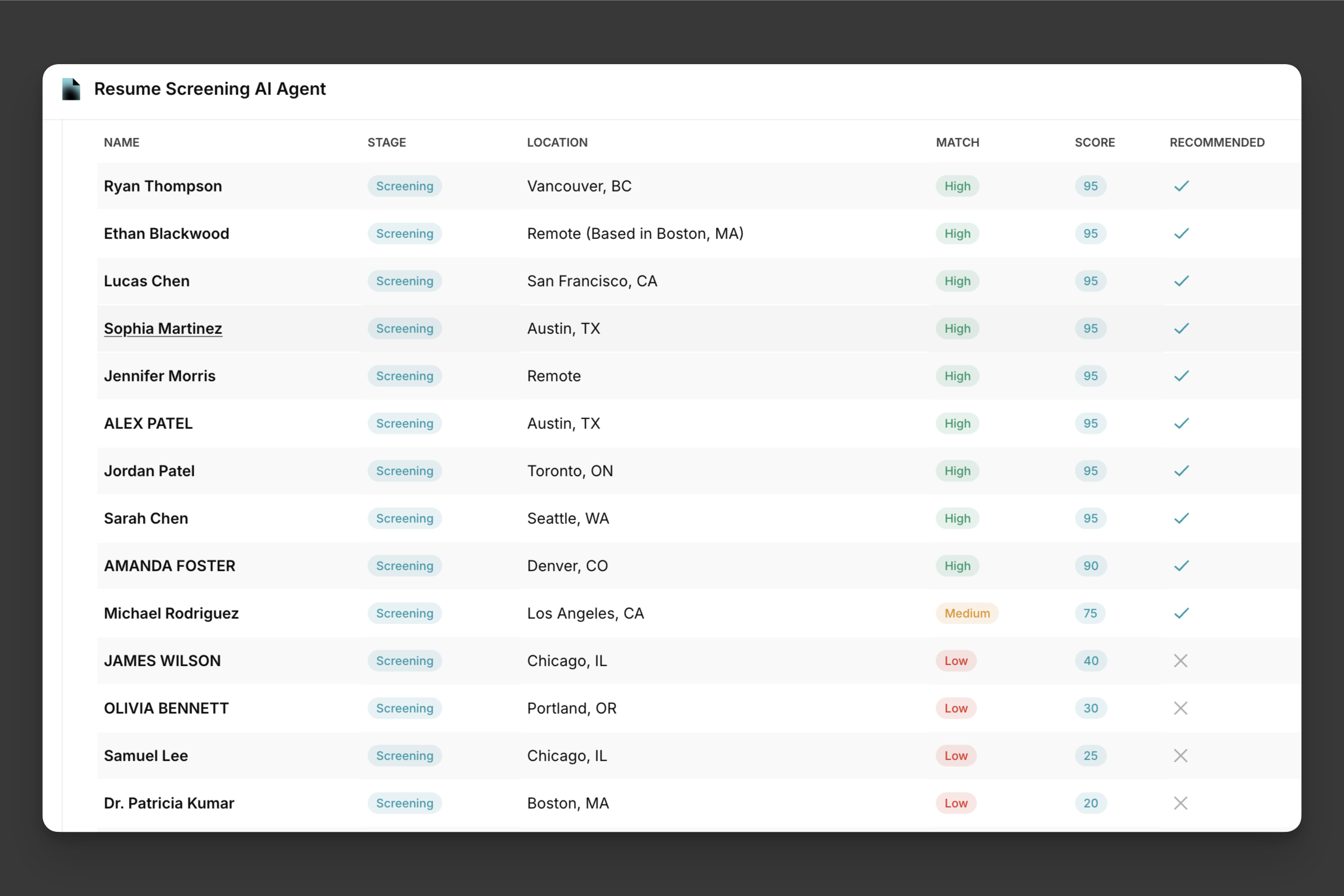
I developed Resume Screener, an end‑to‑end AI‑powered application that helps recruiters automatically rank resumes against job descriptions using a hybrid ranking system combining semantic similarity, keyword relevance and impact‑scoring. Built with a production‑ready full‑stack architecture — frontend via Streamlit for recruiter interaction and backend via FastAPI (Python/ASGI with Uvicorn) for compute‑heavy NLP pipelines — the system uses SentenceTransformers (model “all‑mpnet‑base‑v2”) for embeddings, spaCy (en_core_web_sm) and Scikit‑learn TF‑IDF + FuzzyWuzzy for keyword matching, and PDFPlumber / NLTK for PDF parsing and text preprocessing. Containerised using Docker and docker‑compose for reproducibility and scalability, it enables batch processing of multiple resumes per API request and provides explainable scoring breakdowns (semantic 60 % + keyword 30 % + impact 10 %) so recruiters understand why a resume ranked higher. By automating much of the manual screening work, Resume Screener helps reduce recruiter effort, accelerate hiring workflows and improve match quality — transforming traditional keyword‑filter based screening into a smarter actionable tool ready for real‑world deployment.
 June 7, 2024
June 7, 2024
It is a Retrieval-Augmented Generation system that automates compliance validation against PCI-DSS and ISO 27001, two of the most widely adopted global security standards. Traditional compliance audits are time-intensive and costly, often requiring teams to manually sift through thousands of policy documents — a process that can take weeks. CompliGuard reduces this effort to minutes. By ingesting and semantically chunking large policy PDFs (~81,000 words) and mapping them to compliance frameworks, it produces clear, auditable gap reports. This enables organizations to identify missing clauses, prioritize high-risk areas, and prepare for external audits with precision. In practical terms, this approach can help enterprises save up to 60–70% of the manual review time, lower the risk of audit failures that can cost millions in fines, and strengthen their overall security posture. Beyond time savings, CompliGuard provides executives with a living knowledge base — ensuring that compliance isn’t just a checkbox for audits but an active, ongoing safeguard against breaches and reputational damage.
 May 2, 2024
May 2, 2024
Developed a robust machine learning solution to predict patient readmission risks within 30 days, leveraging a 1-million-row synthetic healthcare dataset. Engineered 10+ key features, including encounter duration and frequency, to train an XGBoost model achieving an AUC-ROC of 0.85, 70% precision, and 65% recall. Built a real-time Dash dashboard with 6 interactive visualizations (e.g., risk heatmaps, trend lines) and integrated a Flask API to deliver updates every 10 seconds, flagging 15% of patients as high-risk for intervention. The project, hosted on GitHub, demonstrates expertise in Python, data preprocessing, and scalable web deployment.
 May 2, 2024
May 2, 2024
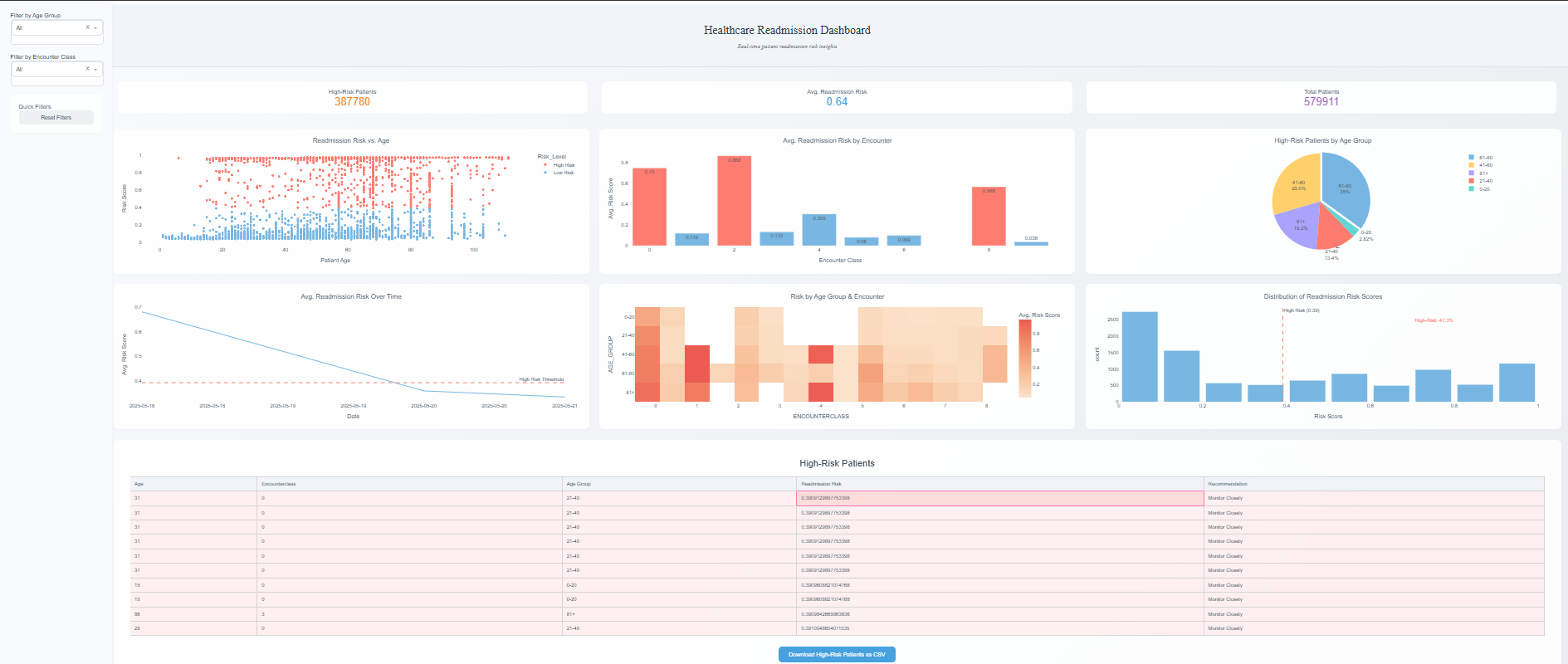
In this project, I developed a real-time earthquake monitoring dashboard that processes and visualizes global seismic data, offering businesses and disaster management agencies actionable insights. The dataset contains over 200,000 rows and grows every hour as new data is ingested from the USGS API. Key metrics like total earthquake count, average magnitude, and regional earthquake trends are visualized through dynamic Power BI dashboards.